If you believe the headlines, large language models (LLMs) will magically reinvent how generative AI (genAI)-powered business applications get built: “Just jam your knowledge into a fine-tuned, vector-embedding, prompt-engineered large language model from one of the big players.”
Things just aren’t that easy. You need way more than a customized large language model to build and operate a genAI-powered business application. That simplistic approach won’t scale, won’t be cost-effective, won’t fully protect you, and won’t put all your proprietary knowledge to work.
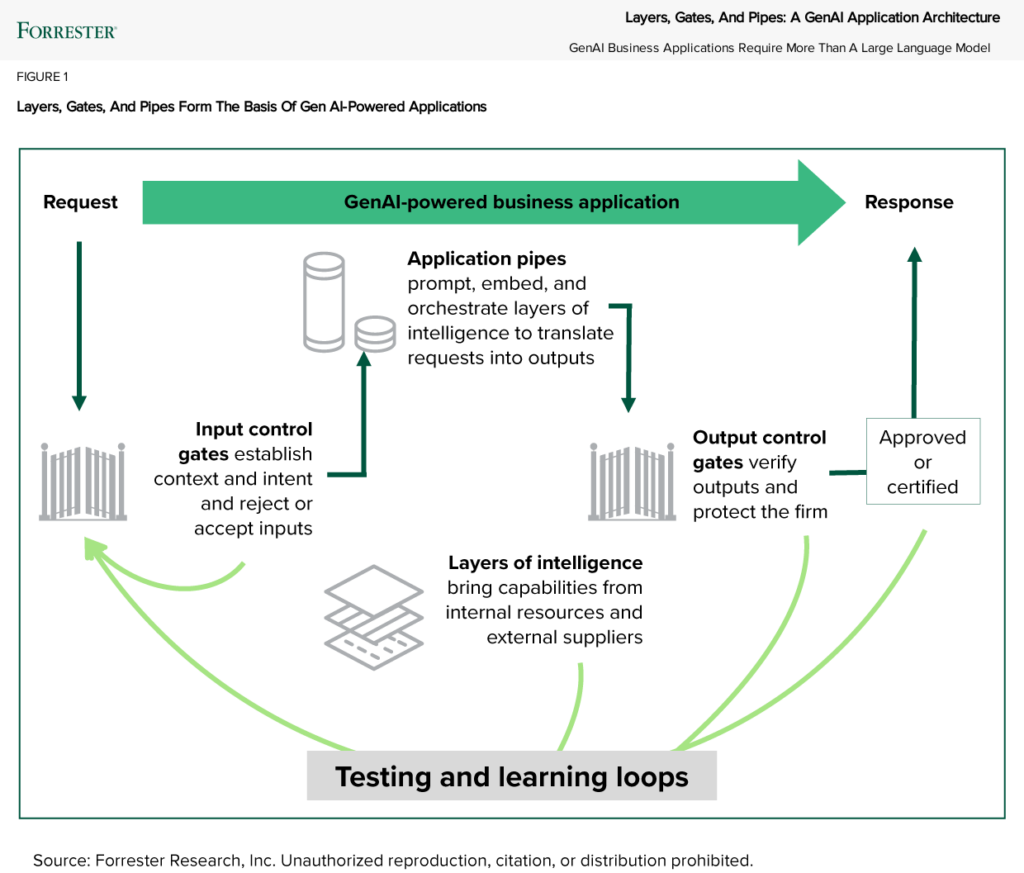
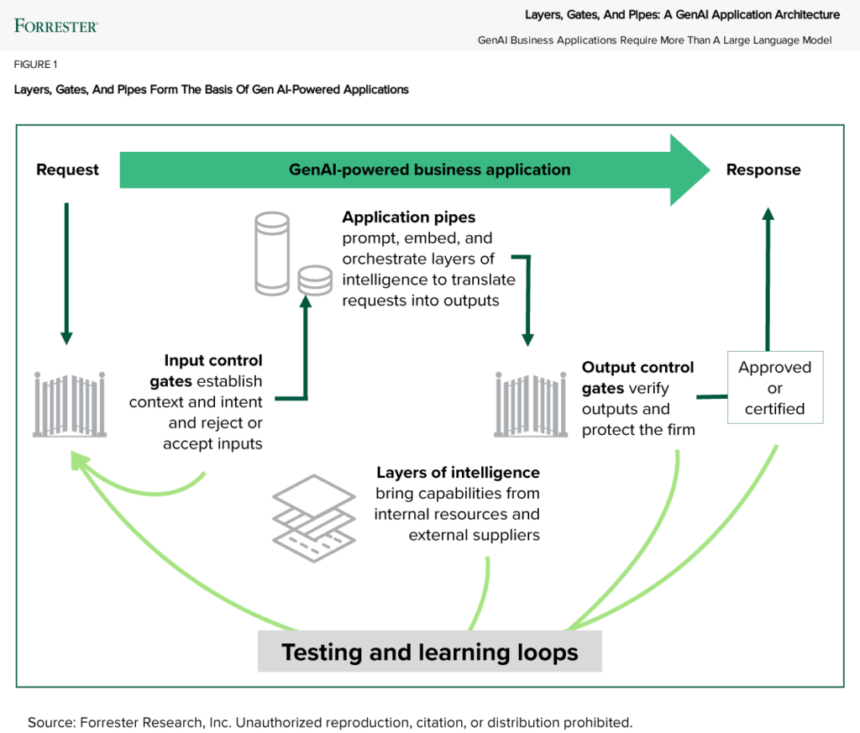
To find a better way, we stepped back, examined best practices, and talked to 15 of the largest service providers about how they are using genAI themselves and how they help Global 2000 companies build genAI-powered business applications. With that as input and after months of discussion, we identified a more comprehensive genAI application architecture that we call layers, gates, pipes, and loops (see figure):
- Layers of intelligence that bring together internal and external capabilities. Layers of intelligence include a staggering array of capabilities, including general-purpose, specialized, and embedded genAI models and tools from suppliers as well as your own knowledge models. For example, consider the layers that capture your knowledge for a customer service chatbot or give your sales teams tools to incorporate your products, value proposition, and competitor battle cards into their pitch presentations. You should also incorporate capabilities from your ML and AI models, software, and more.
- Input and output control gates to protect people, the firm, and the models themselves. Input gates turn away bad requests and turn vague requests into answerable prompts. An HR chatbot for employees shouldn’t be generating software code, but it should be great at answering detailed benefits questions. Input gates also keep models safe by rejecting requests that could lead them astray. Output gates of many kinds validate outputs for security, regulatory compliance, nonsense checks, bad-content filters, brand compliance, and more — before releasing the response (often with a person as the final decision-maker).
- Application pipes to prompt, embed, and orchestrate capabilities to generate responses. You’ll use a long-established development technique called pipes to use APIs to tap all the resources from your layers of intelligence, each prompted in turn. The orchestration comes from making sure that the API calls flow seamlessly from end to end, just like steps in a production line on a factory floor. This API-centric, loosely coupled architecture does the heavy lifting. It also provides the platform to implement your dashboards and capabilities to monitor, manage, and operate the application.
- Testing and learning loops to test apps, monitor results, and make adjustments. Feedback loops are the fourth part in the architecture. They are vital to establishing validity, trust, and confidence in the application. GenAI-powered apps are pulsing, vibrating organisms. Just like a power plant or Jurassic Park, they need constant care. You’ll not only test the heck out of a genAI-powered application before turning it on, but you’ll also watch it and retest it continuously to make sure it doesn’t get out of line. You’ll monitor for quality, performance, costs, and drift.
Let’s Connect
If you’re a Forrester client and would like to learn more, please set up a time for us to talk. I can help direct you to the best analyst to speak with if I’m not the best person. You can also follow or connect with me on LinkedIn if you’d like. If your company has expertise to share on this topic, feel free to submit a briefing request.