Enterprises experimenting with generative AI (genAI) are prioritizing use cases that enable internal and external users to better retrieve information they need, be it data, how-to pages, corporate policies, or return policies. Retrieval-augmented generation (RAG) is now the most common underlying approach for building this type of large language model (LLM)-based enterprise knowledge-retrieval application. What is RAG, and why is it so useful? In a series of blog posts, we will explore the latest developments in RAG architecture, starting with this first one focused on the basics that explain the motivation for implementing RAG. Let’s first review RAG-less architectures and explore their limitations.
System Prompts To Align Basic Outputs
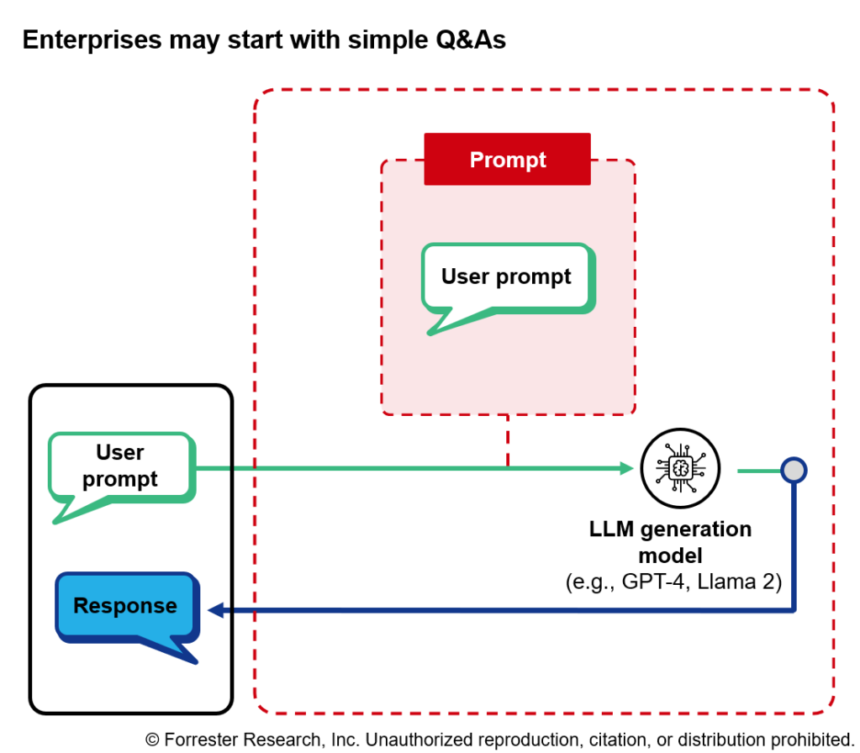
The simplest LLM-based application directly feeds a user’s natural language query (known as a “prompt”) to an off-the-shelf LLM, and the LLM then sends a natural language response back to the user (see below figure). This approach is as easy to build as a simple API call, but it won’t work for building an enterprise knowledge application. An off-the-shelf foundation model has no knowledge of your enterprise’s data, and it also doesn’t know how you expect it to respond. You may want the model to behave like an internal IT help desk agent summarizing call transcripts, but it won’t know anything about your systems, policies, or procedures. We can begin to fix the behavior issue with a system prompt.
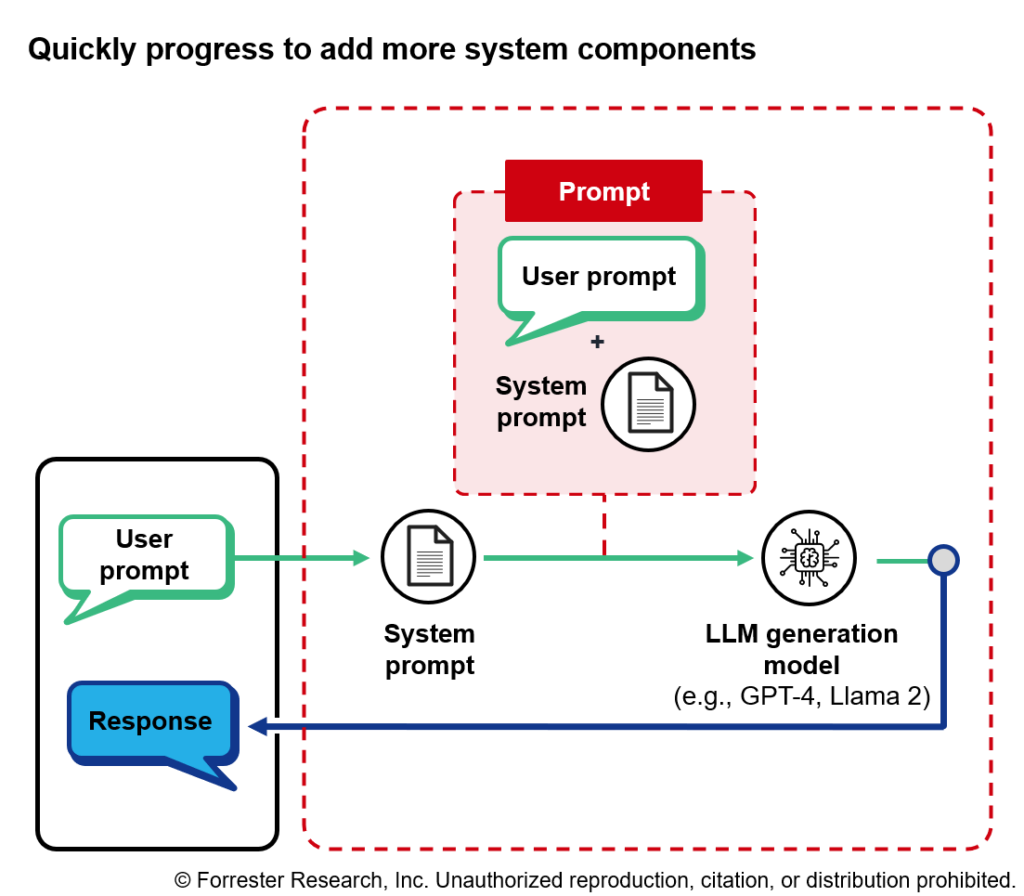
A system prompt is the starting point for ensuring that an application responds in a manner consistent with the designer’s expectations and the system’s requirements. A system prompt explicitly tells the model what it is, what’s expected of it, and how it should respond to queries (e.g., not responding on specific topics or explaining why it responded in a certain way). System prompts are programmed to be appended to user queries, ensuring that each query is evaluated in accordance with the system prompt (see below figure). System prompts can be dozens of lines long, including information on the chatbot’s persona (e.g., you are an AI programming assistant named “Sonny”), boundaries for what the bot can discuss (e.g., you must refuse to discuss life, existence, or sentience), and how to process queries (e.g., first, think step by step: Describe your plan for what to build in pseudo-code, written out in great detail).
Use RAG To Retrieve The Information Needed To Answer A Question
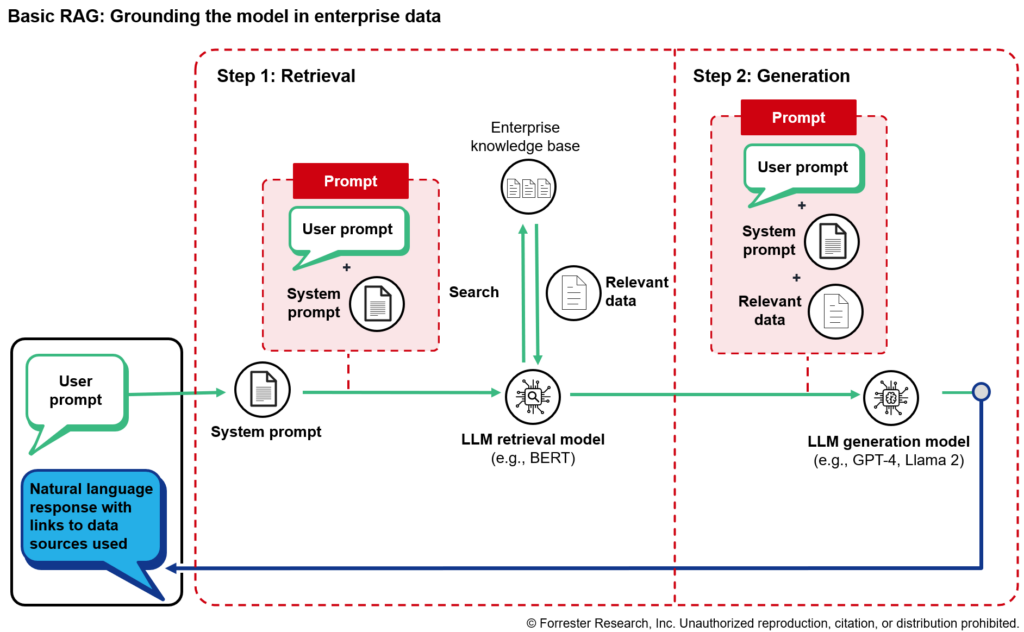
Now to address the issue of providing answers specific to your company’s data: Without access to enterprise data, an application won’t be useful for connecting customers or employees with that enterprise knowledge. If we want an LLM to be able to reference enterprise information, we need to provide it with access to a repository of that information and enable it to search for what it needs. This is the essence of RAG. Think of RAG as an open-book exam (the type of exam where students can bring notes and textbooks). Open-book exams test students on two sets of skills: finding the information they need to answer a question and using critical reasoning to turn that information into insightful and coherent responses.
The RAG approach is to break the process of responding to user prompts into two steps, using a different type of model for each step (see below figure):
- Find the data needed to answer the user’s query (using a retrieval model).
- Craft a response using both the original user query and the relevant data from step 1 (using an answer generation model).
For step 1, retrieval, many companies are using a vector search approach, but this is not required; simpler methods, like keyword search, are also viable options. An example of this is a user asking the application how many sick days they are entitled to — first, the retrieval model fetches the relevant passages from an enterprise knowledge base of HR information (a stored set of documents), then it passes that information to an LLM response generation model along with the user and system prompt. The generation model uses all this information to craft a response that answers the user’s question.
This architecture still has major limitations. The application can tell the user the range of sick days typically available to employees (e.g., “employees are allotted 12–20 sick days, depending on length of tenure and seniority”), but it cannot craft a user-specific response due to lack of knowledge of the user’s tenure, seniority, etc. It has context to ground its answer, but it doesn’t have the context of the user to fully understand the intent. In the next blog in this series, we’ll explain how to address this limitation — and others — with more complex RAG architectures and the option of fine-tuning a model on enterprise data rather than using RAG. If you’d like to dig in more or have questions about adopting AI and beginning to architect your applications, reach out for an inquiry.